
Introducción
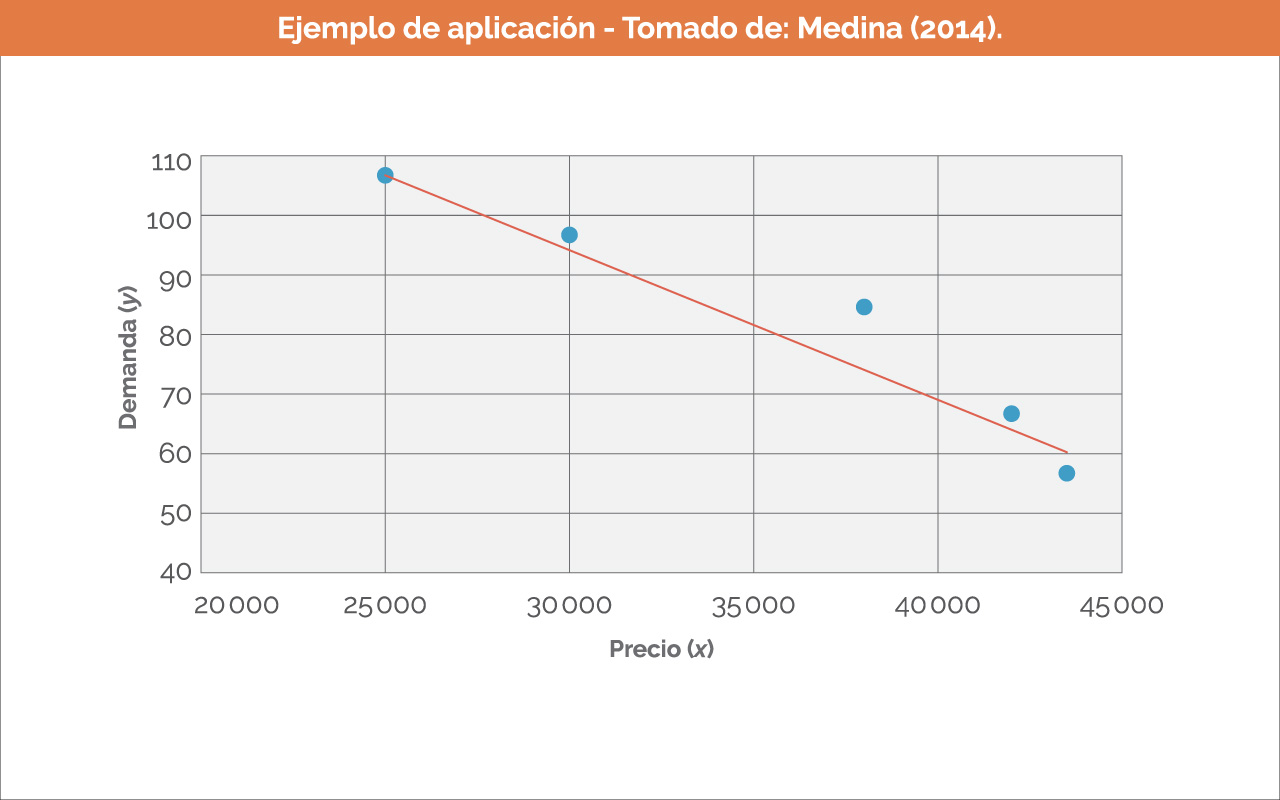
En Ciencias e Ingeniería suelen presentarse problemas en los que se relacionan dos variables, es decir que una variable (dependiente) responda a otra (independiente). Por ejemplo, si un comerciante ofrece un producto a diferentes precios (variable independiente), la demanda (variable dependiente) cambiará en función del precio. Otro ejemplo puede ser la distancia requerida para frenar un automóvil (variable dependiente), la cual es una función de su rapidez (variable independiente).
Si la relación establecida en los ejemplos anteriores es exacta se trata de un «modelo determinista entre dos variables», pues no contiene ningún componente aleatorio o probabilístico. Sin embargo, en dichos ejemplos la relación no es determinística, es decir que a un valor de x no siempre corresponde un mismo valor de y, por lo que el concepto de análisis de regresión tiene que ver con encontrar la mejor relación entre variables aleatorias y cuantificar la intensidad de la relación empleando métodos que permitan calcular los valores de respuesta ante los valores dados del regresor x (Medina, 2014).

Objetivos
Objetivo general
Establecer una función lineal o polinómica a partir de unos datos experimentales para realizar estimaciones entre los datos observados y cuantificar la medida de la calidad de ajuste «coeficiente de determinación».
Objetivos específicos
- Interpolar mediante una función lineal un conjunto de datos y establecer el coeficiente de determinación.
- Interpolar mediante una función polinómica un conjunto de datos y establecer el coeficiente de determinación.
- Resolver problemas de aplicación en Ingeniería y Ciencias.

Recta de regresión y supuestos del modelo
De acuerdo con Medina (2014), en la mayoría de aplicaciones de regresión, una ecuación de la forma:
Es una aproximación simplificada de algo desconocido. «Estas estructuras lineales son sencillas y de naturaleza empírica, por lo que se denominan modelos empíricos». Así las cosas, la respuesta se relaciona con la variable independiente x a través de la ecuación:
En la que a y b son los parámetros desconocidos de la intersección con el eje vertical «a» y la pendiente «b», y ε es una variable aleatoria que se supone distribuida con:
Es habitual que a la cantidad σ2 se le denomine varianza del error o varianza residual. «Como resultado, en la práctica nunca se observan los valores reales, por lo que nunca se puede trazar la verdadera recta de regresión, aunque suponemos que ahí está. Solo es posible dibujar una recta estimada» (Medina, 2014).

Método de los mínimos cuadrados
De acuerdo con Laguna (2014):
El método de los mínimos cuadrados consiste en buscar los valores de los parámetros a y b de manera que la suma de los cuadrados de los residuos sea mínima. Esta recta es la recta de regresión por mínimos cuadrados.
La suma residual de los cuadrados de los errores respecto de la recta de regresión se denota como SSE. Este procedimiento de minimización para estimar los parámetros se llama método de mínimos cuadrados.
 |
A continuación revise los siguientes enlaces para conocer:
|
Varianza de los estimadores
Para realizar inferencias sobre a y b es necesario llegar a una estimación del parámetro σ2 que refleja una variación aleatoria o variación del error experimental alrededor de la recta de regresión. Si se emplea la notación:
El estimador insesgado de σ2 está dado por:
Ejemplo
Calcule el estimador insesgado de σ2 para la expresión anterior y de acuerdo con la tabla que aparece en pantalla.
Solución

Inferencias sobre los coeficientes de regresión pendiente
Un intervalo de confianza «1-α» para el parámetro «β» en la recta de regresión es:
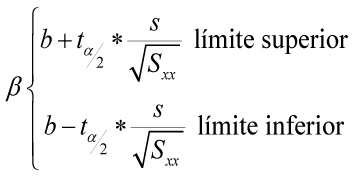
Donde:
b: pendiente de la recta.
ta/2: valor critico en la distribución t de Student para un intervalo de confianza «1-α», con v=n-2 «grados de libertad».
s: desviación estándar de los estimadores.
Consulte la ampliación temática para ver un ejemplo de la aplicación de este concepto.

Johann Carl Friedrich Gauss (Brunswick, 30 de abril de 1777 - Gotinga, 23 de febrero de 1855), fue un matemático, astrónomo, geodesta, y físico alemán que contribuyó significativamente en muchos campos, incluida la teoría de números, el análisis matemático, la geometría diferencial, la estadística, el álgebra, la geodesia, el magnetismo y la óptica. En 1829, Gauss fue capaz de establecer la razón del éxito maravilloso de este procedimiento: simplemente, el método de mínimos cuadrados es óptimo en muchos aspectos. El argumento concreto se conoce como teorema de Gauss-Márkov (Wikipedia, 2017). Retrato hecho por: Jensen (1840).

Inferencias sobre los coeficientes de regresión intersección
Un intervalo de confianza «1-α» para el parámetro «α» en la recta de regresión es:
\alpha \left \{ \alpha +t_{\frac{\alpha }{2}}* \frac{\sum_{i=1}^{n}x_{i}^{2}}{\sqrt{n*s_{xx}}}\right \}Límite superior
\alpha \left \{ \alpha -t_{\frac{\alpha }{2}}* \frac{\sum_{i=1}^{n}x_{i}^{2}}{\sqrt{n*s_{xx}}}\right \}Límite inferior
Donde:
b: pendiente de la recta.
ta/2: valor critico en la distribución t de Student para un intervalo de confianza «1-α», con v=n-2 «grados de libertad».
s: desviación estándar de los estimadores.
En las imágenes que aparecen en pantalla se muestran los pasos para encontrar un intervalo de confianza del 95 % para «α» del ejemplo expuesto anteriormente.
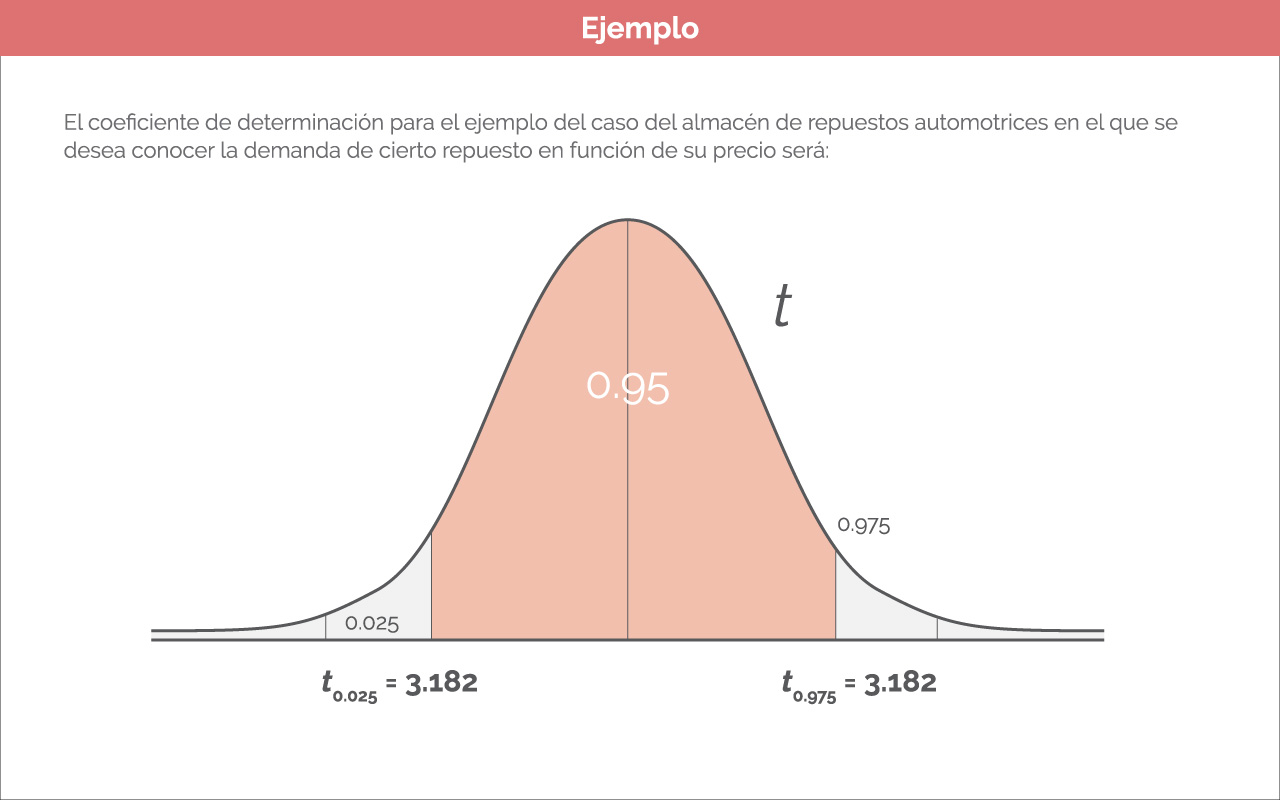

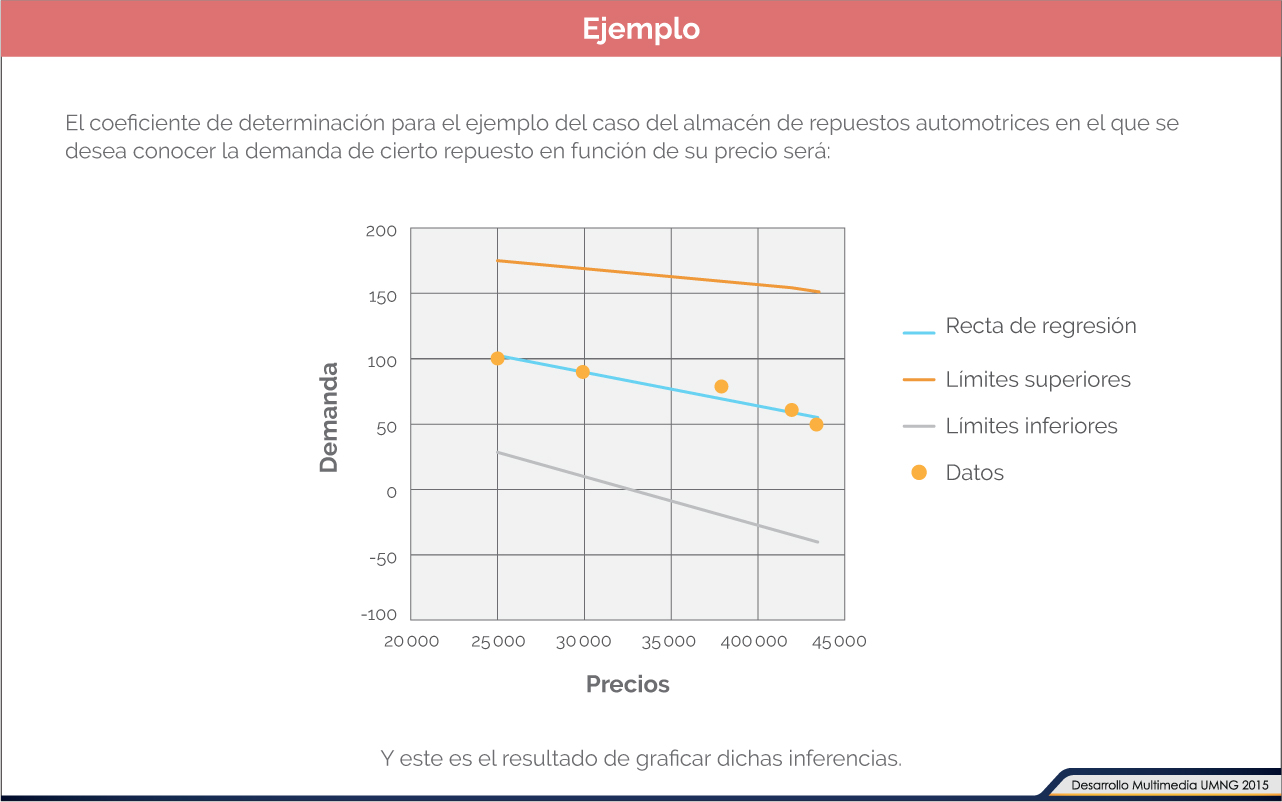
Coeficiente de determinación
El coeficiente de determinación «R2» es la medida de la proporción de la variabilidad explicada por el modelo ajustado, que está dado por:
Donde:
SSE : suma cuadrática de los errores. Es la variación debida al error o variación no explicada.
SST: suma total de los cuadrados corregida. Representa la variación en los valores de respuesta que idealmente serían explicados con el modelo.
En la tabla que aparece en pantalla se halla el coeficiente de determinación para el ejemplo anterior.

Regresión lineal: modelo matricial
Si se traza una recta que se ajuste a la tendencia del conjunto de puntos: (x1, y1), (x2, y2)…, (xn, yn), la recta que presente el mejor ajuste se define como la que minimiza el error de la suma de cuadrados y se denomina «recta de regresión por mínimos cuadrados». El modelo viene dado por:
Donde a0 y a1 son los coeficientes del modelo y vienen dados por:
Las matrices «x^y» se definen como:

Regresión polinomial
Al igual que en la regresión lineal, si se cuenta con un conjunto de datos: (x1, y1), (x2, y2)…, (xn, yn), es posible ajustar un polinomio que modele la tendencia de los mismos minimizando el error de la suma de los cuadrados. El modelo viene dado por:
Teniendo en cuenta que se deben tener mínimo «(n+1)» puntos para generar un polinomio de grado «n», entonces: a0, a1… an son los coeficientes del modelo y vienen dados por:
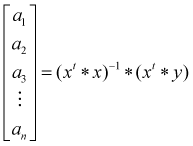
Las matrices «x^y» se definen como:

La regresión también permite generar un polinomio de cualquier grado que se ajuste a «n» puntos. Tal situación se ejemplifica en el ejercicio que se desarrolla en la ampliación temática.
Resumen
En esta unidad se describió el procedimiento para obtener una relación funcional lineal o polinómica entre variables, así como la calidad de ajuste para datos que tienen comportamiento aleatorio.
En tal contexto se abordaron temas como la recta de regresión y los supuestos del modelo; el método de los mínimos cuadrados; la varianza de los estimadores; las inferencias sobre los coeficientes de regresión; el coeficiente de determinación, y la regresión lineal y polinomial.


Bibliografía ()
- Walpole, R., Myers, R., Myers, S., & Keying, Y. (2007). Probabilidad y Estadística para Ingeniería y Ciencia. Editorial Pearson.
Referencias Web
- Jensen, C. (1840). Carl Friedrich Gauss portrait. [Óleo sobre lienzo]. Recuperado de: https://bit.ly/2LLTVHW.
- Laguna, C. (2014). Correlación y regresión lineal. En: Diplomado en Salud Pública. Recuperado de: https://bit.ly/2oDYuWL.
- Medina, O. (2014). Determinación de los parámetros para minimizar el tiempo de soldadura por ultrasonido de la terminal MAK. (Tesis de maestría). Ciateq, San Luís Potosí, México. Recuperado de: https://bit.ly/2KAPca4.
- Wikipedia. (2017). Carl Friedrich Gauss. Recuperado de: https://bit.ly/2fP37HQ.